Types d’apprentissage machine¶
Dans son livre, (Marsland, 2015), a défini l’apprentissage comme le fait de “s’améliorer” dans l’accomplissement d’une tâche grâce à la pratique. Ça consiste donc à faire en sorte que les machines (ordinateurs), en suivant des recettes algorithmiques, modifient ou plutôt adaptent leurs actions pour qu’elles deviennent plus précises afin de donner des résultats justes et acceptables.
Suite à cette définition, deux questions peuvent être soulevées: comment l’ordinateur sait-il s’il s’améliore ou non, et comment sait-il comment s’améliorer? L’auteur propose plusieurs réponses possibles à ces questions afin de cerner les différents types d’apprentissage machine. Il est possible d’indiquer à notre algorithme la bonne réponse à un problème pour qu’il l’obtienne la prochaine fois. Nous espérons que nous n’aurons à lui donner que quelques bonnes réponses et qu’il pourra ensuite trouver comment obtenir les bonnes réponses pour d’autres problèmes similaires (généraliser). Alternativement, nous pouvons lui indiquer si la réponse était correcte ou non, mais pas comment trouver la bonne réponse, de sorte qu’il doit chercher comment trouver cette bonne réponse. Une variante de ceci est que nous donnions un score pour la réponse, en fonction de sa justesse, plutôt qu’une réponse “bonne ou mauvaise” (0, ou 1). Enfin, nous n’avons peut-être pas de bonnes réponses; nous voulons simplement que l’algorithme trouve des entrées qui ont quelque chose en commun.
Apprentissage Supervisé¶
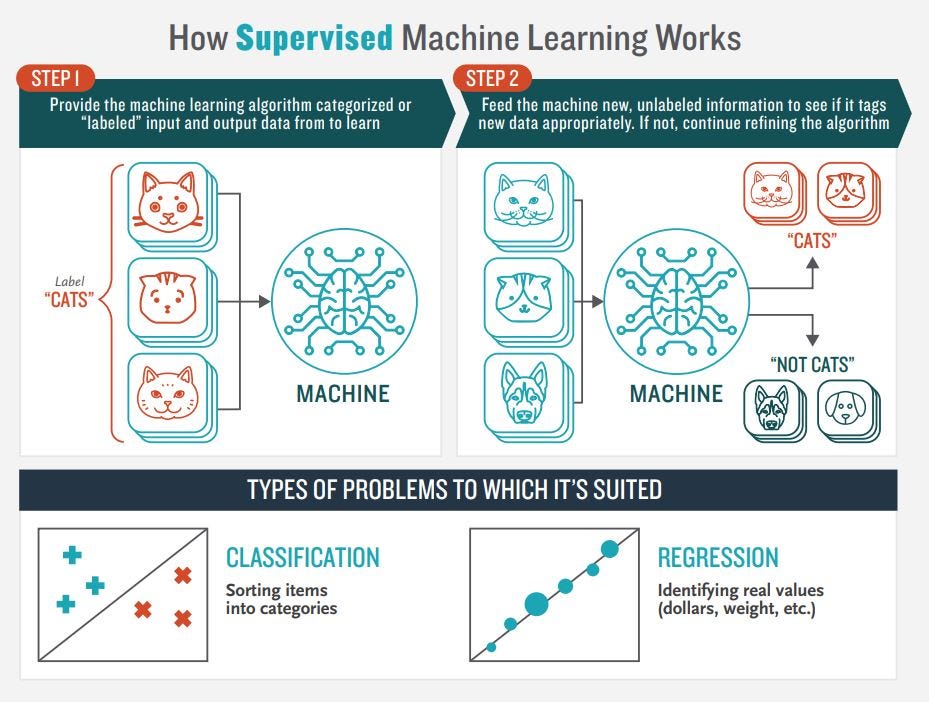
De façon générale, l’apprentissage statistique supervisé consiste à construire un modèle statistique pour prédire ou estimer un résultat en fonction d’une ou plusieurs variables explicatives
Dans ce cas, on utilise un algorithme pour analyser les données d’entraînement afin d’apprendre la fonction qui mappe l’entrée des variables explicatives à la sortie qui est le résultat souhaité.
autrement dit, on cherche à estimer une variable \(Y\) à l’aide d’un ensemble de variables \(\mathbf{X}\)
Cette fonction \(\hat{f}\) déduite mappe de nouveaux exemples inconnus en généralisant à partir des données d’entraînement afin d’anticiper (prédire) \(Y\) dans des situations non vues auparavant.
Avec l’apprentissage non-supervisé, nous sommes capables de résoudre les problèmes de classification ainsi que de régression
Classification¶
Lorsque les données sont utilisées pour prédire une variable catégorielle. C’est le cas lorsqu’on attribue une étiquette ou un indicateur, soit un chien ou un chat, à une image.
Lorsqu’il n’y a que deux étiquettes, on appelle cela une classification binaire. Lorsqu’il y a plus de deux catégories, les problèmes sont appelés classification multi-classes.

Régression¶
Quand on prédit des valeurs continues (“numériques*”), les problèmes deviennent un problème de régression.
Apprentissage non-supervisés¶
Avec l’apprentissage statistique non-supervisés, il y a des entrées mais pas de sortie supervisée
On cherche à apprendre des relations et de la structure à partir des données.
Regroupement ( Clustering )¶
Regroupement d’un ensemble d’exemples de données de sorte que les exemples d’un groupe (ou d’une grappe) soient plus semblables (selon certains critères) que ceux des autres groupes. Ceci est souvent utilisé pour segmenter l’ensemble des données en plusieurs groupes. Une analyse peut être effectuée dans chaque groupe pour aider les utilisateurs à trouver des modèles intrinsèques.


Réduction des dimensions¶
Réduction du nombre de variables considérées. Dans de nombreuses applications, les données brutes ont des caractéristiques dimensionnelles très élevées et certaines caractéristiques sont redondantes ou non pertinentes à la tâche.
Par exemple, compression d’images, analyse de données de télématique …etc.
On dispose d’un jeu de données dans un espace de dimension élevé \(\mathbb{R}^k\) avec \(k\) élevés: \(\mathbf{X}_i=[x_{i1}, x_{i2}, \dots, x_{ik}]\) et \(i=1, \dots, n\)
On cherche une transformation \(g: \mathbf{X}_i \rightarrow \mathbf{X}_i^*\) avec \(\mathbf{X}_i^* \in \mathbb{R}^q\) où \(q <<< k\) en perdant le moins d’information possible.

Apprentissage semi-supervisé¶
Le défi de l’apprentissage supervisé est que l’étiquetage des données peut être coûteux et prendre beaucoup de temps.
Si les étiquettes sont limitées, vous pouvez utiliser des exemples non étiquetés pour améliorer l’apprentissage supervisé.
Avec l’apprentissage semi-supervisé, on utilise des exemples non étiquetés avec une petite quantité de données étiquetées pour améliorer la précision de l’apprentissage.
Apprentissage par renforcement¶
L’apprentissage par renforcement analyse et optimise le comportement d’un agent en fonction des réactions de l’environnement. Les machines essaient différents scénarios pour découvrir les actions les plus payantes, plutôt que de se faire dire quelles actions prendre. Les essais et erreurs et les récompenses différées distinguent l’apprentissage par renforcement des autres techniques.

Voir l’exemple DeepMind de Google
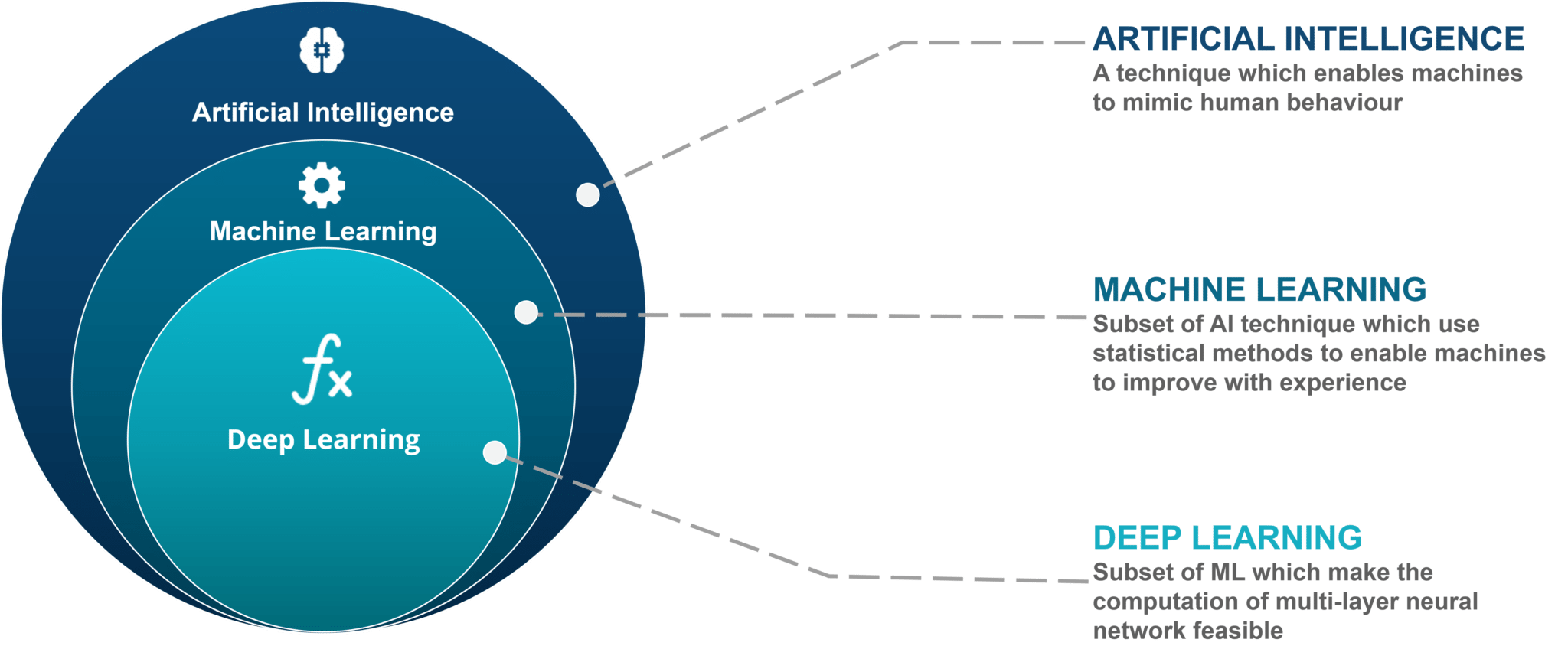
Ai vs ML vs DL¶
Application¶
Des problèmes de cette nature se posent dans des domaines aussi divers que la finance, l’actuariat, la santé publique, l’environnment, l’astrophysique et même la politique