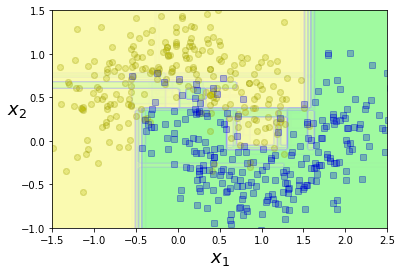
Random forest¶
Les forêts aléatoires offrent une amélioration par rapport bagging grâce à une petite modification qui permet de décorréler les arbres. Comme dans le cas de bagging, nous construisons un certain nombre d’arbres de décision sur des échantillons d’entraînement. Mais lors de la construction de ces arbres de décision, chaque fois qu’une division dans un arbre est envisagée, un échantillon aléatoire de \(m\) prédicteurs est choisi comme candidats à la division parmi l’ensemble complet de \(p\) prédicteurs.
Essentiellement, le bagging implique l’échantillonnage des observations (pour former les ensembles d’entraînement bootstrappés) et les forêts aléatoires impliquent l’échantillonnage à la fois des observations (pour former les ensembles d’entraînement bootstrappés) et des prédicteurs (à considérer pour chaque fractionnement). Généralement, nous fixons \(m \approx \sqrt{p}\), bien qu’il puisse être sélectionné par validation croisée.

from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
import numpy as np
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter="random", max_leaf_nodes=16, random_state=42),
n_estimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1, random_state=42)
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
np.sum(y_pred == y_pred_rf) / len(y_pred)
0.976